
Research
研究紹介
逐次的意思決定AIによる高度プロセス制御
研究概要
図1のように時々刻々と移り変わる周囲の環境に対して,学習主体であるエージェントが試行錯誤を通して合理的な意思決定方法(方策)を自律的に最適化する問題を逐次的意思決定問題とよびます。具体的には,バンディット問題,オンライン凸最適化問題,最適制御問題,強化学習など様々な逐次的意思決定問題の枠組みが存在します。特に,強化学習は深層学習技術を組み合わせることで,アーケードゲームや囲碁に対して,人間のプロプレイヤーと同レベルのプレー方法を自律的に習得できたことで大きな注目を集めました。それ以降も,ロボティクス,自動運転,ゲームAI,レコメンド,ヘルスケアなどの多岐にわたって応用研究が盛んにおこなわれています。
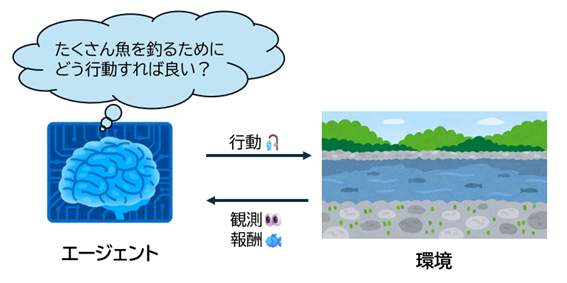
図1:逐次的意思決定の様子。周辺の環境の観測をもとに,得られる報酬が大きくなるよう行動を選択する。
研究内容
当研究室では,このような逐次的意思決定技術を用いたプロセス制御の高度化に関する研究に取り組んでいます。
プロセスとは,図2のように,プラント内で原料等に物理的・化学的変化を加え,高価値な製品を生産する一連の工程をさしており,
このような工程が含まれる化学,鉄鋼,電力,ガス,セメント,製紙,食品加工などの産業は総じてプロセス産業とよばれています。
近年,プロセス産業は,人手不足,カーボンニュートラル,原料・エネルギー価格不安定化の対応など様々な課題を抱えており,
より高度なプロセスの最適化や自動制御範囲の拡大へ向けた一手段として逐次的意思決定AI技術の応用が有望視されています。
当研究室では,単に最先端のAI技術をプロセス制御へ導入することだけではなく,「安全性保証」や「非定常外乱対処」などといったプロセス制御にとって特に重要な課題を深く考察し,
それに合ったアルゴリズムや理論を構築することで,プロセスの現場で使ってもらえる技術の開発を目指しています。
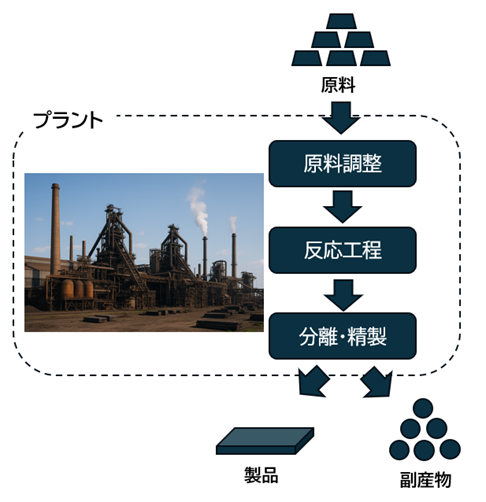
図2: プロセスにおける大まかな流れ。各工程で,所望の製品仕様に合わせてプラント内部のバルブやポンプなどの緻密な調整が行われている。



